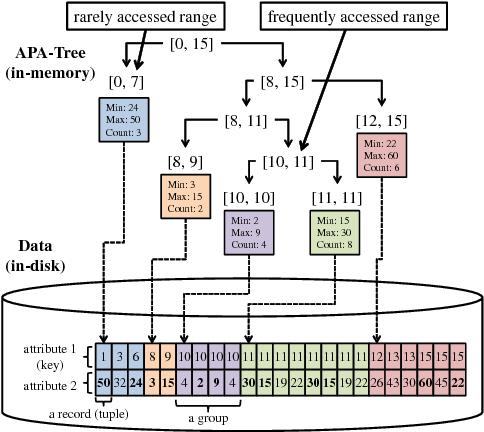
Range aggregation query is a fundamental operation in the feature engineering phase of the machine learning tasks, which computes statistics, such as the maximum and the standard deviation of a subset of records. Since the feature-engineering process is a trial-and-error process, data analysts repeatedly conduct tons of the range aggregation queries by changing the range conditions, which results in a heavy workload. To accelerate such repetitive range aggregation queries, we propose Adaptive Partial Aggregation Tree (APA-tree), which drastically reduces the amount of I/Os that happen in executing the range aggregation queries. The APA-tree partitions the data into several groups, executes range aggregations on each subgroups to obtain partial results, and caches the results in an imbalanced binary-tree. The APA-tree executes subsequent queries by reusing the cached partial query results as much as possible on the basis of the divide-and-conquer characteristic of the range aggregations. Experimental results confirm that APA-tree outperforms conventional partial aggregation methods regarding the amount of I/Os, especially in a skewed workload.