
Think Deeper, Generate Less
Accepted to AI4Science @ ICMLUnder the same token budget, algorithm discovery improved more by spending tokens on stronger individual program edits than by generating more candidates.
Research Scientist / AI Systems
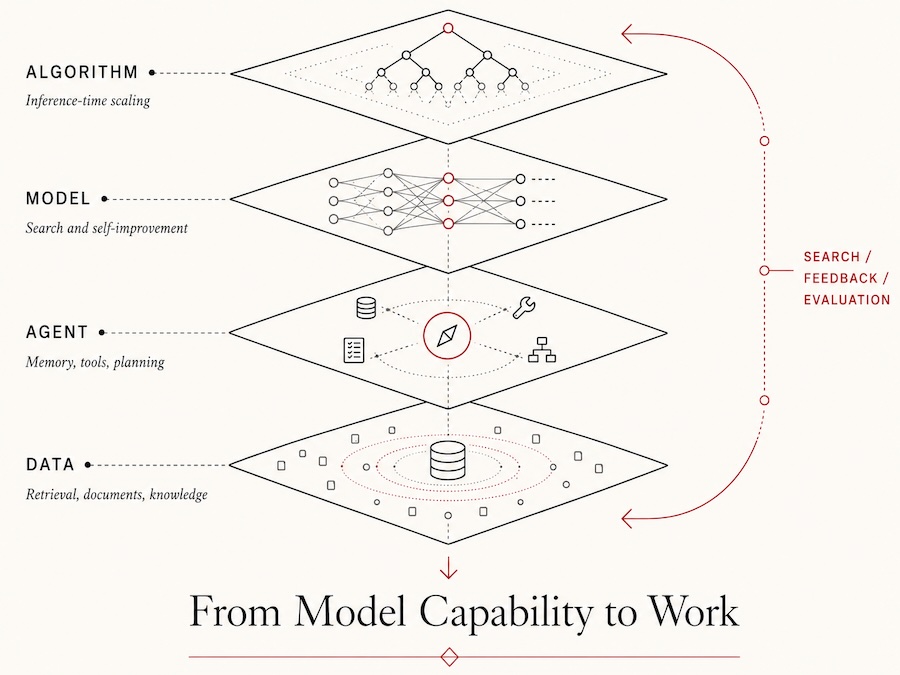
Humans did not beat the condor by becoming better animals; they did it by building the bicycle. I see machine intelligence similarly: progress comes not only from stronger models, but from the algorithms, tools, memory, feedback loops, and data systems that amplify them.
I study AI capability as a layered systems problem: Algorithm, Model, Agent, and Data.
At the algorithmic layer, I work on inference-time methods that draw more reasoning from a fixed model. At the model layer, I study search and feedback loops that help models improve. At the agent layer, I build composable systems that combine memory, tools, observations, and planning. At the data layer, I study how retrieval, documents, tables, and external knowledge ground AI in real tasks.
Recent projects include test-time scaling, self-improving agents, workplace-learning browser automation, retrieval-augmented generation, and data-centric AI.
Latest Notes
Under the same token budget, algorithm discovery improved more by spending tokens on stronger individual program edits than by generating more candidates.
Browser agents usually know the page but not the organization behind the task.
Automated reviewers aligned best with human judgments when guided by official conference criteria, not by prompts that imitate reviewer behavior.
More generations can improve LLM answers, but majority voting has a limit.
Research Archive
Research highlights on the algorithms, agents, retrieval systems, and data infrastructure that amplify language models.
Masafumi Enomoto, Ryoma Obara, Haochen Zhang, Masafumi Oyamada
Coverage aligns closely with end-to-end success while requiring far less evaluation time.
End-to-end web-agent evaluation can take hundreds of hours. Minimal Failure Sets turn it into a lightweight coverage question: does a shortened HTML observation keep the elements that actually make the task succeed?
Yoichi Ishibashi, Taro Yano, Masafumi Oyamada
Runs that spend more tokens per algorithm cluster near higher Circle Packing scores.
Under the same token budget, algorithm discovery improved more by spending tokens on stronger individual program edits than by generating more candidates. On Circle Packing, this suggests a quality-per-iteration bottleneck for evolutionary search with coding agents.
Masafumi Oyamada, Kunihiro Takeoka, Kosuke Akimoto, Ryoma Obara, Masafumi Enomoto, Haochen Zhang, Daichi Haraguchi, Takuya Tamura
Ordinary browsing is distilled into a shared knowledge workspace that both users and agents can use.
Browser agents usually know the page but not the organization behind the task. cotomi Act turns ordinary browsing into shared memory: task boards, timelines, and wiki knowledge that the agent can consult as future work unfolds.
Haowen Li, Yoichi Ishibashi, Masafumi Oyamada
RMSE comparisons show that rubric-style reviewer-imitating guidelines often move LLM scores farther from human judgments.
Automated reviewers aligned best with human judgments when guided by official conference criteria, not by prompts that imitate reviewer behavior. The result suggests that peer-review automation needs carefully designed evaluation standards, while overly rigid rubrics can push LLM scores away from human assessments.
Masafumi Enomoto, Ryoma Obara, Haochen Zhang, Masafumi Oyamada
Lower-capability web agents improve with compact observations, while stronger models benefit from richer page context and more thinking budget.
Web-agent context is not just a compression problem. The best page representation changes with model capability and thinking budget, so observation pipelines should adapt to the agent rather than standardize on one reduced format.
Junpei Komiyama, Daisuke Oba, Masafumi Oyamada
Accuracy improves with more generations but flattens near the asymptotic majority-vote limit.
More generations can improve LLM answers, but majority voting has a limit. Best-of-infinity studies the N → ∞ regime to separate the accuracy a model could reach with unlimited sampling from the finite compute needed to get close.
Nobuhiro Ueda, Yuyang Dong, Krisztián Boros, Daiki Ito, Takuya Sera, Masafumi Oyamada
SCAN groups fragmented page elements into larger semantic regions that preserve document context.
Rich documents are hard for RAG because a page can mix charts, text, titles, and images. SCAN shows that retrieval improves when chunks follow semantic regions instead of tiny layout fragments, giving LLMs and VLMs the context they need without processing whole pages.
Jonathan Light, Wei Cheng, Benjamin Riviere, Wu Yue, Masafumi Oyamada, Mengdi Wang, Yisong Yue, Santiago Paternain, Haifeng Chen
DISC adapts reasoning step boundaries instead of committing to a fixed whole-solution, token-level, or sentence-level split.
LLM inference scaling often depends on where a solution is split into steps. DISC makes that boundary adaptive: it uses rollout feedback to use coarser steps when progress is clear and finer steps when a decision looks risky, improving compute efficiency across math and coding benchmarks.
Taro Yano, Yoichi Ishibashi, Masafumi Oyamada
LaMDAgent searches post-training pipelines by looping through action enumeration, action selection, model evaluation, and memory updates.
LaMDAgent reframes model adaptation as an iterative design loop: enumerate possible training actions, build a candidate model, evaluate it, and remember what worked. The key idea is that an LLM agent can search over complete post-training pipelines, not just tune isolated hyperparameters.
Takuya Tamura, Taro Yano, Masafumi Enomoto, Masafumi Oyamada
The lineage-aware method tracks actual benchmark performance more closely across BBH, IFEval, MATH, MMLU-Pro, and the aggregate score.
Model ancestry carries performance information. When LLMs are fine-tuned or merged, their descendants often inherit enough structure from their parents that a lineage-aware predictor can forecast benchmark behavior more accurately.
Gorjan Radevski, Kiril Gashteovski, Shahbaz Syed, Christopher Malon, Sebastien Nicolas, Chia-Chien Hung, Timo Sztyler, Verena Heußer, Wiem Ben Rim, Masafumi Enomoto, Kunihiro Takeoka, Masafumi Oyamada, Goran Glavaš, Carolin Lawrence
SynQA reaches high attribution F1 with a 1B model while much larger baselines trail behind.
A small attribution model can become competitive when the training data has the right structure. SynQA shows that synthetic evidence paths can train a 1B-parameter model to identify answer-supporting context across several QA settings.
Yusuke Yamauchi, Taro Yano, Masafumi Oyamada
Across BIGGENBench and EvalBiasBench, removing criteria or references changes LLM-judge reliability across evaluator models.
LLM judges are more reliable when they receive explicit evaluation criteria, not just a reference answer. For open-ended tasks, reliability is shaped by how scoring is specified, and that design choice can materially change results even with the same evaluator model.
Kenya Abe, Kunihiro Takeoka, Makoto P. Kato, Masafumi Oyamada
Expansion improves retrieval mainly when the query matches knowledge the model already has.
LLM query expansion is not a free retrieval boost. It helps when the model already has enough knowledge about the query, but can hurt search quality when the query asks about unfamiliar concepts or under-specified intent.
Shintaro Ozaki, Yuta Kato, Siyuan Feng, Masayo Tomita, Kazuki Hayashi, Wataru Hashimoto, Ryoma Obara, Masafumi Oyamada, Katsuhiko Hayashi, Hidetaka Kamigaito, Taro Watanabe
Retrieval shifts answer probabilities from an overconfident wrong choice toward the evidence-supported medical answer.
A retrieved passage can make a model more or less certain even when the final answer is the same. This work treats output probability as a signal for how medical LLMs respond to evidence, revealing behavior that accuracy alone can miss.
Yoichi Ishibashi, Taro Yano, Masafumi Oyamada
LLM-designed merging rules outperform the seed model and human-designed baselines on GSM8k while matching the best MATH score.
The work asks whether a language model can invent useful model-improvement algorithms, not just apply human-written ones. In model merging, self-generated Python algorithms improve GSM8k from 70.1% to 76.1% and match the strongest MATH result among the compared human-designed methods.
Haochen Zhang, Yuyang Dong, Chuan Xiao, Masafumi Oyamada
Across six data-preprocessing tasks, Jellyfish turns 7B-13B base models into much stronger local solvers with large average gains.
Jellyfish shows that local 7B-13B LLMs can become strong data-preprocessing solvers when tuned on task descriptions, injected knowledge, and reasoning traces. The key lesson is practical: for cleaning tables, targeted instruction data can unlock large gains without relying only on bigger hosted models.
Yuyang Dong, Masafumi Oyamada, Chuan Xiao, Haochen Zhang
The material moves from table-task basics to five LLM strategies: prompting, fine-tuning, RAG, agents, and vision-language models.
How should LLMs be used with tabular data? Table-aware LLM work can be organized around five practical routes: prompting, fine-tuning, RAG, agents, and vision-language models, making a fast-moving design space easier to compare and apply.
Masafumi Enomoto, Kunihiro Takeoka, Kosuke Akimoto, Kiril Gashteovski, Masafumi Oyamada
LightPAL moves from a directly retrieved passage to indirectly relevant context by walking a passage graph.
Broad summarization queries often need passages that do not match the query directly. LightPAL treats retrieval as navigation through a passage graph, using random walks to surface indirectly relevant context while improving retrieval and summarization metrics in many settings.
Kosuke Akimoto, Masafumi Oyamada
As target-language data becomes scarcer, multilingual two-stage training overtakes the single-stage alternatives in this setting.
Low-resource LLM training is not simply a matter of repeating scarce data more often. As target-language data shrinks, the best setup can shift from monolingual single-stage training to multilingual two-stage training, with the switch point depending on compute.
Haochen Zhang, Yuyang Dong, Chuan Xiao, Masafumi Oyamada
LLMs rival specialized preprocessors on several tabular benchmarks, while gaps remain across tasks and datasets.
Tabular preprocessing asks whether LLMs can operate over structured records, not just fluent text. Across error detection, imputation, schema matching, and entity matching, the results are promising but uneven: LLMs can rival specialized tools on some benchmarks, while efficiency and reliability still shape their practical value.
Taro Yano, Kunihiro Takeoka, Masafumi Oyamada
Keyword augmentation is framed as a two-stage process: generate candidate terms from class names, then rerank them for relevance, exclusivity, and diversity.
Effective keyword augmentation for zero-shot text classification depends on more than semantic similarity. REDEX ranks candidate keywords by task-aware relevance, inter-class exclusivity, and intra-class diversity, improving performance across fully zero-shot and generalized zero-shot settings.
Krisztián Boros, Masafumi Oyamada
Single-call, networked, and hierarchical agent organizations route summarization work through different communication patterns.
Can LLMs summarize better by working as an organization? This work models summarization as a DAG of cooperating LLM agents and shows a practical lesson: network-like and hierarchical workflows can improve faithfulness or quality in some settings, but the best structure depends on the task.
Haochen Zhang, Yuyang Dong, Chuan Xiao, Masafumi Oyamada
Raw data preprocessing tasks are converted into instruction data for tuning compact local Jellyfish models.
Can data preprocessing get LLM-style flexibility without sending sensitive tables to an external API? Jellyfish shows that instruction-tuned 7B-13B local models can handle multiple data cleaning tasks on modest hardware while keeping data closer to where it lives.
Yuyang Dong, Chuan Xiao, Takuma Nozawa, Masafumi Enomoto, Masafumi Oyamada
DeepJoin combines training, offline indexing, and online search into a vector-retrieval pipeline for joinable columns.
DeepJoin reframes joinable-table discovery as learned retrieval. Instead of comparing raw column values one by one, it trains a language model so joinable columns land near each other in vector space, then uses approximate nearest-neighbor search to find candidates quickly.
Genki Kusano, Masafumi Oyamada
Optimal transport spreads the music attribute "opera" across nearby movie attributes instead of forcing a single label match.
If “opera” in music is close to several movie genres, its influence should be distributed across them, not forced into one hand-made label match. ATP uses optimal transport to translate preference weight between attribute spaces, then compares users after that translation.
Kosuke Akimoto, Kunihiro Takeoka, Masafumi Oyamada
Exact-match accuracy shifts sharply when FiD is trained on contexts whose evidence quality differs from the evaluation setting.
Retrieval-augmented QA depends not only on the passages supplied at inference time, but also on the quality of passages seen during training. FiD can overfit to that context quality, so a model trained on clean evidence may lose accuracy when retrieval becomes noisier.
Yuyang Dong, Masafumi Oyamada
The interface compares model performance before and after enrichment while showing the added columns that feed the prediction task.
Table augmentation is only valuable if it improves the model that will use it. The system makes enrichment an evaluable workflow: add external columns, train with the enriched table, and compare prediction quality before and after enrichment.
Kunihiro Takeoka, Kosuke Akimoto, Masafumi Oyamada
Musubu maintains higher Edge-F1 than the baselines across low-resource training sizes.
The useful signal for taxonomy enrichment is not only in the seed taxonomy. Musubu uses pretrained language models as a source of implicit parent-child knowledge, improving parent prediction when only a small number of hierarchy examples are available.
Kazunori Sakai, Yuyang Dong, Masafumi Oyamada, Kunihiro Takeoka, Takeshi Okadome
A transformed pair can move toward stronger agreement; the size of that movement becomes a matching feature.
Entity matching breaks when two names look similar for the wrong reason, or different for a superficial one. The key idea is to measure how similarity changes after string transformations, so a gain or drop becomes evidence about whether two records name the same entity.
Genki Kusano, Masafumi Oyamada
Linking purchase and browsing histories reveals cross-domain behavior that a single service would miss.
Can two accounts be matched when all you see is behavior, not demographics? Purchase logs and browsing logs can support likely identity matches when their histories are mapped into a shared behavioral representation.
Masafumi Enomoto, Kunihiro Takeoka, Yuyang Dong, Masafumi Oyamada, Takeshi Okadome
Partial annotations still identify useful regions of the class hierarchy, even when the exact leaf label is missing.
Crowdsourced hierarchical labels often stop before the most specific class. Instead of discarding those incomplete answers, this method combines the label hierarchy with worker-specific reliability to improve leaf-label estimation.
Yuyang Dong, Kunihiro Takeoka, Chuan Xiao, Masafumi Oyamada
PEXESO builds an offline vector index so online queries can retrieve joinable tables by similarity.
Data lakes hide useful joins behind spelling variants, formatting differences, and semantic near-matches. PEXESO embeds textual table values as high-dimensional vectors, so join discovery can search by similarity in value space rather than exact string equality.
Yuyang Dong, Chuan Xiao, Hanxiong Chen, Jeffrey Xu Yu, Kunihiro Takeoka, Masafumi Oyamada, Hiroyuki Kitagawa
Each object update is first matched to affected queries, then only those top-k lists are refilled.
When people, posts, or devices move and change keywords, continuous spatial-keyword search can be maintained efficiently by treating each update as a targeted repair. The system identifies only the registered queries whose top-k answers may change, then refills those lists with grid-indexed spatial and keyword evidence.
Kunihiro Takeoka, Yuyang Dong, Masafumi Oyamada
Unsure responses cluster near the dog-wolf decision boundary, showing how hesitation can identify difficult training examples.
When annotators choose Unsure, they may be flagging the hardest examples rather than adding unusable noise. This work treats those responses as boundary information, letting classifiers learn from ambiguity instead of throwing it away.
Masafumi Oyamada
Notebook code is transformed into typed syntax trees so repeated feature-engineering operations can be discovered across projects.
Expert feature engineering often hides in ordinary notebook code, but naming differences make those operations difficult to reuse. This work turns code into typed syntax patterns so recurring transformations can be discovered across data-analysis projects.
Kunihiro Takeoka, Masafumi Oyamada, Shinji Nakadai, Takeshi Okadome
Neighboring columns help resolve an ambiguous numeric Height column against labels such as Age or Temperature.
A column’s meaning is rarely contained in its header alone. Meimei uses cell values and neighboring columns as context, so a numeric field like height is not confused with age or temperature just because the values look plausible.
Masafumi Oyamada
Frequently accessed ranges get finer cached summaries, letting later aggregation queries reuse more prior work.
Feature engineering often asks the same range-aggregation question in slightly different ways. APA-tree caches partial aggregate results in an adaptive tree, so later queries can reuse prior work instead of rereading the same records from disk.
Masafumi Oyamada, Jianquan Liu, Shinji Ito, Kazuyo Narita, Takuya Araki, Hiroyuki Kitagawa
Runtime speedups vary by compression scheme, but the compressed representations extend useful acceleration from sparse bag-of-words data to dense datasets where ordinary sparse storage performs poorly.
Sparse formats are efficient only when the data really stays sparse. CVS asks whether one compressed representation can handle both sparse and dense vector sets efficiently, while still supporting the operations needed by learning algorithms.
Masafumi Oyamada, Shinji Nakadai
Customer groups and item groups are learned together, then each customer group gets its own demographic prediction model.
A single demographic predictor assumes the same behavioral signals matter for every customer. R-iSVM learns customer and item clusters from purchase histories, then trains a local expert for each customer group, using behavior as interpretable model structure rather than hand-built features.
Masafumi Oyamada, Hideyuki Kawashima, Hiroyuki Kitagawa
The same stream events can produce different aggregates depending on whether the query reads one resource version or mixes versions.
Streaming systems often need mutable reference data, but ordinary continuous-query execution does not guarantee a consistent view of it. This work adapts database concurrency control to streaming: two-phase locking, snapshots, and optimistic validation preserve serializable results while processing continues.
Masafumi Oyamada, Hideyuki Kawashima, Hiroyuki Kitagawa
Asynchronous invocation lets later stream tuples move forward while earlier transaction results are still pending.
High-rate data streams can stall when every tuple waits for its database transaction to finish. Decoupling transaction invocation from result waiting improved throughput by an order of magnitude in the reported experiments, while an order-preserving variant kept results aligned with the stream.
Archive
Our paper "Effective Harness Engineering for Algorithm Discovery with Coding Agents" has been accepted to AI4Science @ ICML 2026.
Our paper "cotomi Act: Learning to Automate Work by Watching You" has been accepted to ACM CAIS'26 (Demos).
Our paper "Evaluating the Impact of Reviewer Guideline Design on LLM-Based Automated Peer Review" has been accepted to ACL 2026 (Findings).
Our paper "Best-of-∞ -- Asymptotic Performance of Test-Time Compute" has been accepted to ICLR 2026.
Our paper "SCAN: Semantic Document Layout Analysis for Textual and Visual Retrieval-Augmented Generation" has been accepted to EACL 2026 (Findings).
Our paper "DISC: Dynamic Decomposition Improves LLM Inference Scaling" has been accepted to NeurIPS 2025.
NEC's cotomi Act achieved world-first success rate of 80.4% on WebArena benchmark, surpassing human performance (78.2%) in web browser automation tasks! Press Release
Our paper "LaMDAgent: An Autonomous Framework for Post-Training Pipeline Optimization via LLM Agents" has been accepted to EMNLP 2025.
Our paper "Can a Crow Hatch a Falcon? Lineage Matters in Predicting Large Language Model Performance" has been accepted to COLM 2025.
Our paper "On Synthesizing Data for Context Attribution in Question Answering" has been accepted to ACL 2025.
Our paper "LLM-based Query Expansion Fails for Unfamiliar and Ambiguous Queries" has been accepted to SIGIR 2025.
Our paper "Understanding the Impact of Confidence in Retrieval Augmented Generation: A Case Study in the Medical Domain" has been accepted to BioNLP2025 (Workshop colocated with ACL2025).
Our paper "Can Large Language Models Invent Algorithms to Improve Themselves?" has been accepted to NAACL 2024 main track!
Presented on Self-Improving LLM, RAG, and Action Model at the ComSys 2024 Conference.
Our poster paper "Towards Automated Workflow Construction for AI Agents: A Preliminary Study" has been accepted to IEEE Big Data 2024.
Our paper "Jellyfish: Instruction-Tuning Local Large Language Models for Data Preprocessing" has been accepted to EMNLP 2024.
Presented on Real-world Large Language Model Development and Recent Research Trends (such as Test-time Compute) at Kobe University.
Presented at ACM MM'24 on NEC's large language model development.
Presented on Self-Improving LLM, RAG, and Action Model at the organized session of LLM and Data Management in WebDB Summer Workshop.
Our tutorial "On the Use of Large Language Models for Table Tasks" has been accepted to CIKM 2024.
Presented at IPSJ Seminar on NEC's large language model development.
Our paper "Relevance, Diversity, and Exclusivity: Designing Keyword-augmentation Strategy for Zero-shot Classifiers" has been accepted to *SEM@NAACL 2024.
Our paper "DeepJoin: Joinable Table Discovery with Pre-trained Language Models" has been accepted to VLDB 2023.
Our paper "Towards Large Language Model Organization: A Case Study on Abstractive Summarization" has been accepted to IEEE Big Data 2023.
Our paper "Context Quality Matters in Training Fusion-in-Decoder for Extractive Open-Domain Question Answering" has been accepted to EMNLP Findings 2023.
Our paper "QA-Matcher: Unsupervised Entity Matching Using a Question Answering Model" has been accepted to PAKDD 2023.
Our paper "Table Enrichment System for Machine Learning" has been accepted to SIGIR 2022.