Many annotation systems provide to add an unsure option in the labels, because the annotators have different expertise, and they may not have enough confidence to choose a label for some assigned instances. However, all the existing approaches only learn the labels with a clear class name and ignore the unsure responses. Due to the unsure response also account for a proportion of the dataset (e.g., about 10-30% in real datasets), existing approaches lead to high costs such as paying more money or taking more time to collect enough size of labeled data. Therefore, it is a significant issue to make use of these unsure.
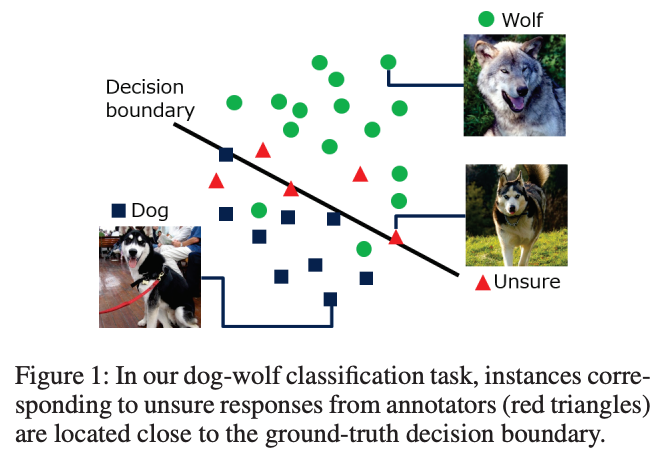
In this paper, we make the unsure responses contribute to training classifiers. We found a property that the instances corresponding to the unsure responses always appear close to the decision boundary of classification. We design a loss function called unsure loss based on this property. We extend the conventional methods for classification and learning from crowds with this unsure loss. Experimental results on realworld and synthetic data demonstrate the performance of our method and its superiority over baseline methods.