Extracting Feature Engineering Knowledge from Data Science Notebooks
Designing good features for machine learning models, which is called feature-engineering, is one of the most important tasks in data analysis. Well-designed features, which capture the characteristics of data, improve the predictive performance and explainability of the model. Since good features generally reflect the deep knowledge on business domains of the data and the analysis task, feature engineering is considered as one of the most difficult phases in data analysis.
Nowadays, AutoML is trying to automate the data science process by producing good features by autonomous algorithms such as feature-synthesis and feature-selection. While AutoML is making success in some extent, it cannot reproduce all the features crafted by expert data scientists in reality because of its huge search space.
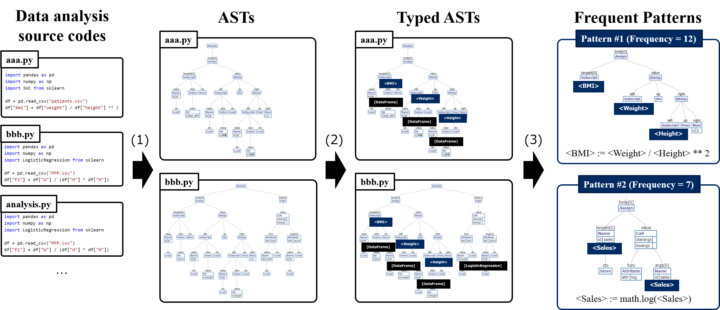
In this paper, we take different approach for assisting feature engineering process: transfer expert data scientists knowledge as much as possible. Proposed approach extracts frequently used feature engineering operations from source codes or notebooks by pattern discovery. Since naive textual pattern discovery performs poor for the source code, our approach converts source codes into abstract syntax trees and discovers important feature engineering operations as subgraphs by performing frequent subgraph mining.